ImageNet classification with deep convolutional neural networks (AlexNet)
AlexNet paper by [1] Krizhevsky et al. was published in 2012. It is a highly influential paper in computer vision which showed that deep networks along with efficient utilization of GPUs for training can help build better models. They were able to achieve top-1 and top-5 test set error rates of 37.5% and 17.0%, while the best in ILSVRC 2010 was 47.1% and 28.2%.
Introduction
Before 2008, the computer vision researchers mostly evaluated their methods on datasets with tens of thousands of images. Thanks to the ImageNet dataset [2] which was published in 2009, researchers got the opportunity to move from small scale datasets such as MNIST, CIFAR-10/100 to a much larger dataset which has over 15 million labeled images from more than 22,000 categories.
The ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) [3] which started in 2010 focuses on a subset of ImageNet which has 1.2 million training images, 50,000 validation images, and 150,000 testing images.
Architecture
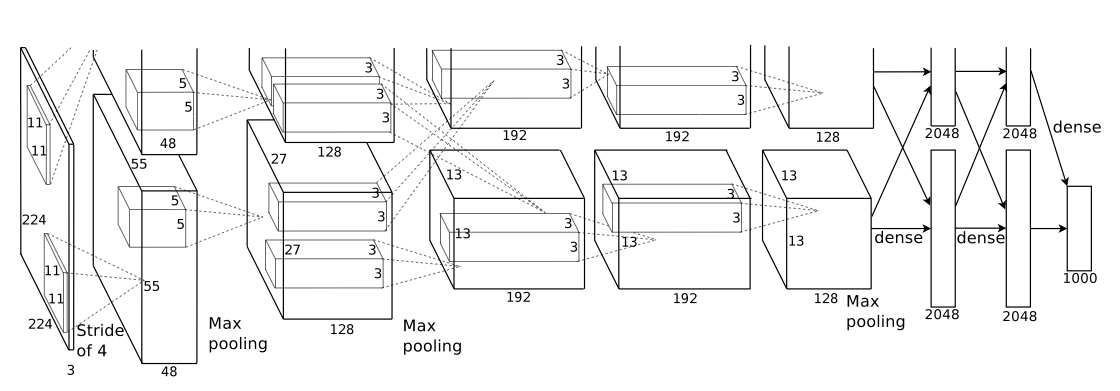
Key characteristics of the AlexNet architecture :
8 learned layers (5 Conv, 3 Fully-connected)
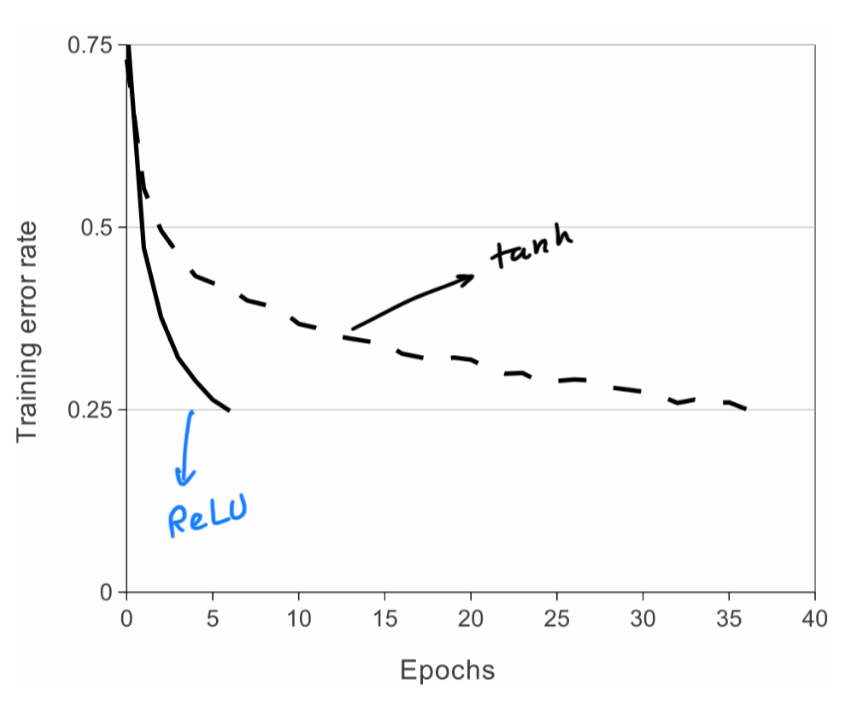
1. ReLU nonlinearity
Inspired by Nair and Hinton's work [4] , authors have utilized the ReLU non-linearity and have found that it makes the training process several times faster.
2. Multiple GPU Training
Authors employ a cross-GPU parallelisation approach to train the AlexNet and the communication between GPUs happen only when it is required by the certain layers. They utilize 2x GTX 580 GPUs.

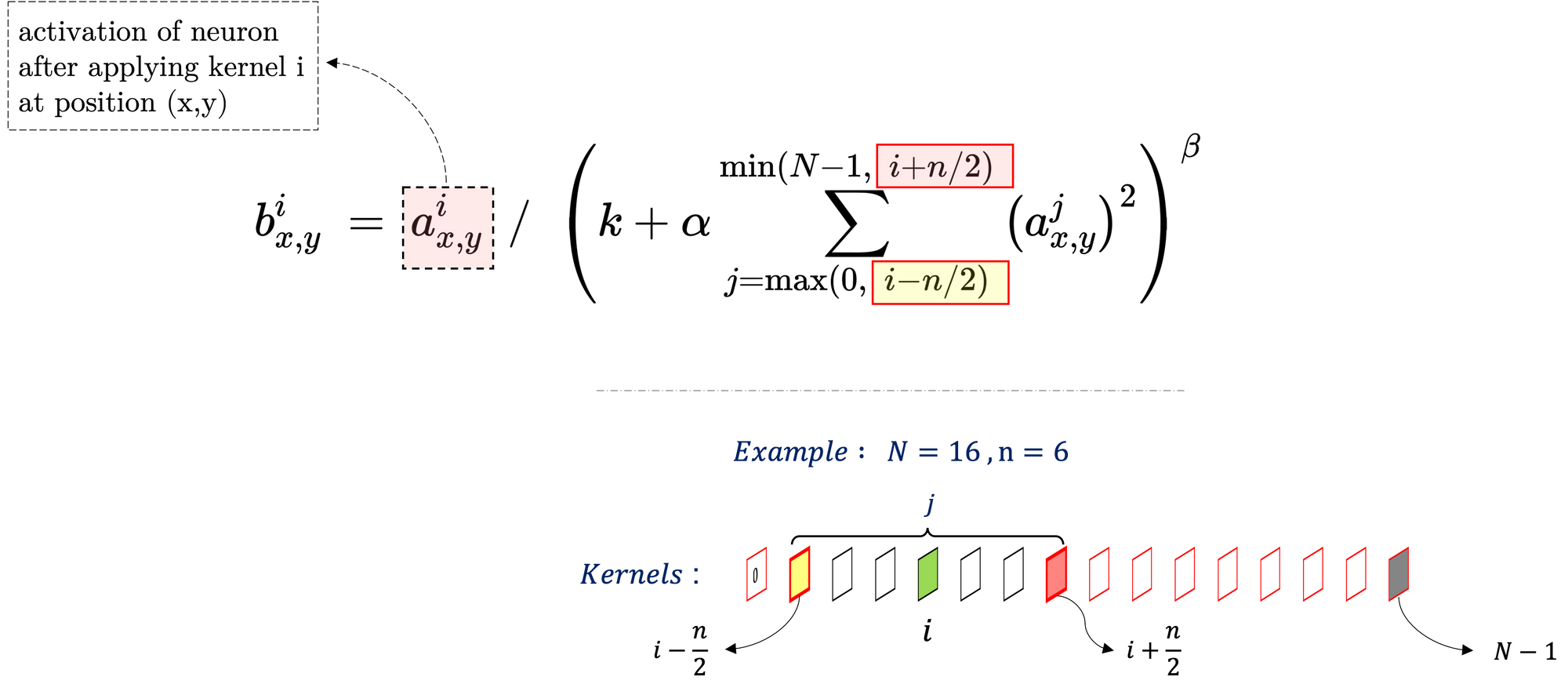
3. Local Response Normalization
Krizhevsky et al. has found that their local normalization methods helps achieve better generalization. For this procedure, they sum over $n$ adjacent kernel maps at the same spatial location as shown in the equation below. This normalization has been applied in certain layers of AlexNet.
4. Overlapping Pooling
By overlapping pooling scheme has reduced top-1 and top-5 error rates by 0.4% and 0.3%. Furthermore, the authors have observed that models with overlapping pooling are slightly more difficult to overfit.
Reducing Overfitting
Authors have utilized 1) data augmentations, 2) dropout to reduce overfitting. Data augmentation has been done in two ways.
1) Generating image translations and horizontal reflections
2) Altering RGB channel intensities in training images
Authors cite their early work on Dropout [6] and mention that it has reduced overfitting substantially while roughly doubling the number of training iterations needed to converge.